

皆さん、こんにちは。どんぶラッコです。
今回は、プログラミング未経験者に対して、HTMLとWebブラウザの関係性を説明した時の資料を公開しようと思います。
Webページを作るにはHTML!だからHTMLを書くべきなんだ!
という教育本をよく目にしますが、これだけだとHTMLとWebブラウザの関係性まで理解できませんよね?
ということで、今回はWebブラウザとHTMLファイル間のやり取りについてストーリー形式でまとめてみました!
前提条件
プログラムの大原則として 上から順番に実行されるというものがあります。
この前提が抜けてしまうと理解が追いつかなくなってしまうことがあるので気をつけましょう!
Webブラウザが情報を表示するまでの流れ
例えば、 http://hoge.com というサイトにアクセスをしたとしましょう。
すると、Webブラウザ(ChromeやFirefox)はhttp://hoge.comという場所にある index.htmlを読み取ろうと動きます。
index.htmlにセリフをつけるとしたらこんな感じです。

そんなindex.htmlの要望に応え、Chromeが読み取りを開始します。

この時、拡張子が .html であることから、WebブラウザのChrome君は、HTMLを読みとる前提で解読を進めていきます。
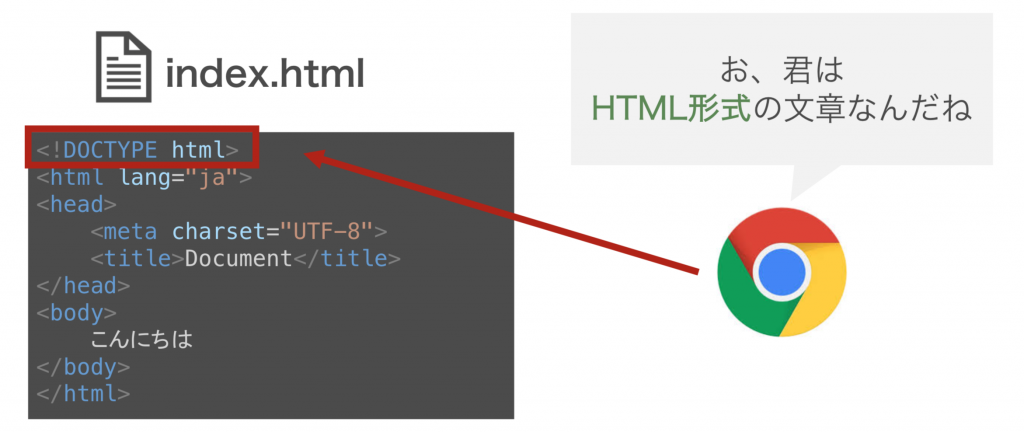
ちなみに、1行目の部分でも再度HTMLであることを確認しています。

ということで、WebブラウザはHTMLのルールに従って解読を進めていきます。

headの部分で設定を読み込み…

bodyで表示情報を読み込む…

その結果、表示がされる、という流れです。
上の物語もそうですが、私はよく擬人化することで、理解を深めることが多いです。
そうすることによって、普段は無機質に見えているやり取りが、ストーリー性を持って理解することができるからです。
皆さんもぜひチャレンジしてみてください!


















